The Day OpenAI Hit the Panic Button: The High-Stakes Release of GPT-5.2
Facing its most serious competitive threat yet, OpenAI declared an internal 'Code Red,' marshaling its resources to release GPT-5.2—a three-pronged model family designed to win back its crown.
On December 11, 2025, OpenAI released GPT-5.2, its most advanced model series for professional work. While officially a planned launch, its arrival was shadowed by reports of an internal "Code Red" declared by CEO Sam Altman, a company-wide directive to urgently improve ChatGPT amid soaring pressure from rivals, particularly Google's highly-regarded Gemini 3. This release wasn't just another update; it was a strategic counterpunch in an AI arms race that had, for the first time in years, seen OpenAI playing catch-up.
The Competitive Inferno: Why "Code Red" Was Called
For years, OpenAI enjoyed a seemingly unassailable lead. The launch of ChatGPT in 2022 defined the modern AI era, and its models were considered best in class. However, by late 2025, the landscape had dramatically shifted.
- The Gemini 3 Shock: Google's release of the Gemini 3 model in November was a watershed moment. It seized the top spot on major third-party performance leaderboards, wowing the industry with its capabilities and presenting the most direct threat yet to OpenAI's dominance.
- A Crowded Frontier: Anthropic's Claude Opus 4.5 also launched with impressive gains, particularly in long-context reasoning. OpenAI was suddenly facing an "array of worthy challengers", and its response could not be business as usual.
Internally, this pressure forced a stark reprioritization. Ambitious projects, including work on introducing ads to ChatGPT, were sidelined. Resources were marshaled toward a singular goal: rapidly improving the core model to close the quality gap. As OpenAI's head of applications, Fidji Simo, stated, the "Code Red" was announced "to really signal to the company that we want to marshal resources in one particular area".
GPT-5.2: The Three-Faceted Response
OpenAI's answer was not a single, monolithic model. Instead, GPT-5.2 debuted as a segmented family of three models, a strategic move to balance the high computational cost of advanced reasoning with diverse user needs for speed and accuracy.
- GPT-5.2 Instant: Optimized for speed, this is the model for daily driving—quick writing, translations, and information-seeking.
- GPT-5.2 Thinking: The star of the release and the direct answer to rivals. Designed for "complex, structured work," it leverages deep, chain-of-thought reasoning to excel at coding, math, and multi-step projects.
- GPT-5.2 Pro: The uncontested heavyweight, delivering the highest accuracy for the most difficult scientific and technical questions where quality outweighs all other concerns.
The Comeback Metrics: Does GPT-5.2 Retake the Lead?
OpenAI positioned GPT-5.2 as its "most capable model series yet for professional knowledge work," and the benchmark results were deployed to make that case emphatically.
Key Performance Claims for GPT-5.2 Thinking:
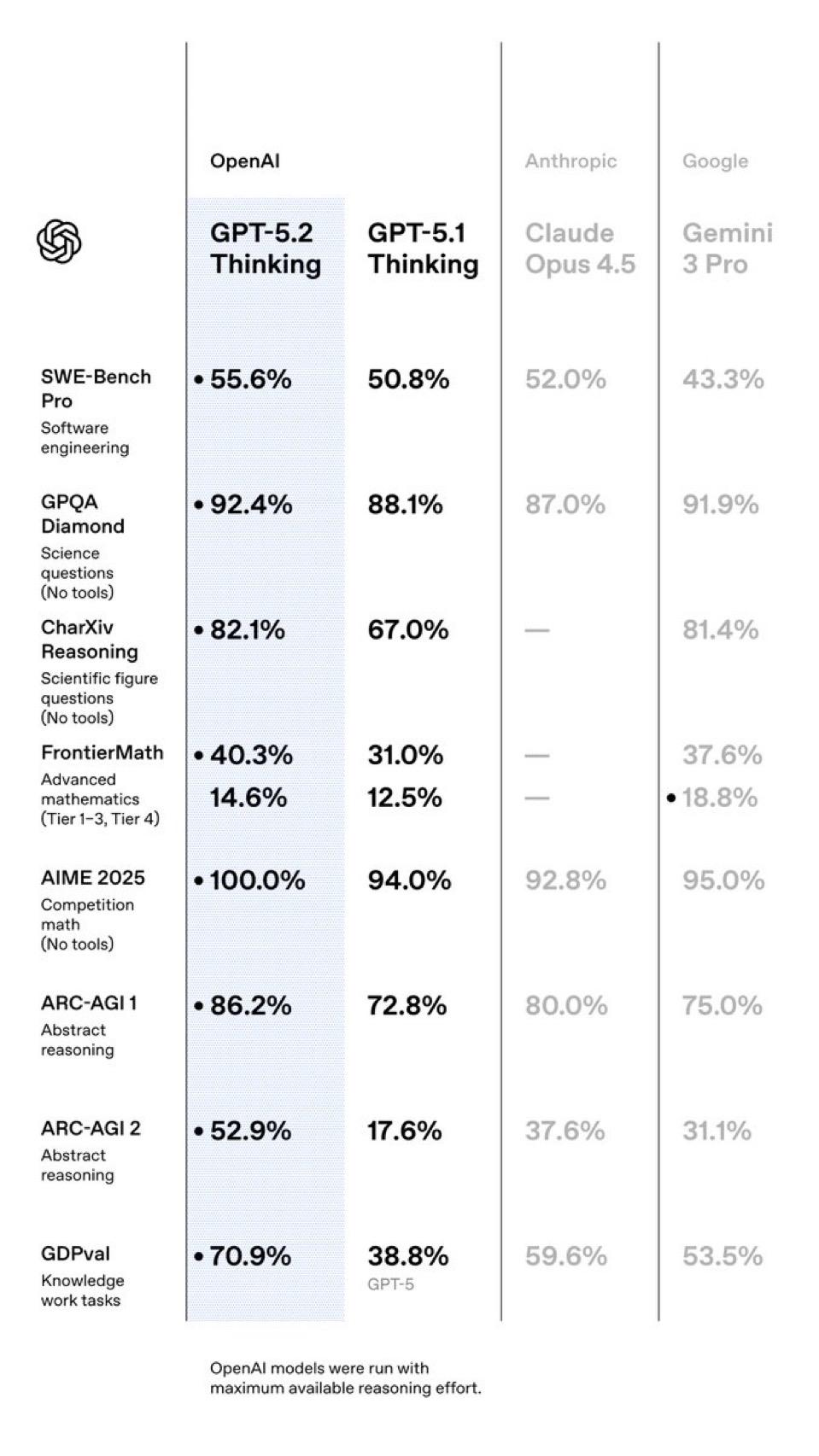
- Human-Level Professional Work: On the GDPval benchmark, which tests well-specified tasks across 44 occupations, GPT-5.2 Thinking beat or tied top industry professionals on 70.9% of comparisons. OpenAI notes it performed this work at over 11 times the speed and less than 1% of the cost of the professionals.
- Elite Software Engineering: It set a new state-of-the-art score of 55.6% on SWE-Bench Pro, a rigorous, industrially-relevant evaluation of real-world software engineering.
- Advanced Reasoning & Science: The model achieved 100% on the 2025 AIME math competition and 92.4% on the graduate-level GPQA Diamond science benchmark.
- Enhanced Reliability: Factual errors (hallucinations) were reduced by approximately 38% compared to GPT-5.1.
While these numbers are impressive, the competitive reality is nuanced. OpenAI executives have pointed out that some benchmarks where competitors lead, like SWE-bench Verified, are considered less "contamination resistant" and "industrially relevant" than their preferred SWE-Bench Pro. Furthermore, Altman himself downplayed the immediate impact, stating that Google's Gemini 3 had "less of an impact on the company's metrics than it originally feared".
The Enterprise Calculus: Power at a Price
For businesses, GPT-5.2 promises a leap into the "mega-agent" era, with a massive 400,000-token context window enabling deep analysis of huge document sets or code repositories. Early enterprise testers like Box and Notion reported significant boosts in reasoning accuracy and task speed.
However, this power comes with a premium, especially for the flagship "reasoning" models.
- GPT-5.2 Thinking is priced at $1.75 per million input tokens and $14 per million output tokens in the API.
- GPT-5.2 Pro commands a top-tier rate of $21/$168 per million tokens.
OpenAI argues that the models' greater efficiency and ability to solve tasks in fewer steps justify the cost for high-value workflows. This pricing firmly positions GPT-5.2 as a premium tool for professional and enterprise use, where the return on investment is measured in expert hours saved.
A Temporary Reprieve in a Never-Ending Race
The release of GPT-5.2 has momentarily stabilized OpenAI's position. The "Code Red" focus worked, delivering a model that meets or exceeds the current frontier on key professional benchmarks. Altman expects the company to exit the emergency footing by January.
But the tempo of the AI race has changed forever. The days of six-month victory laps are over. Google, Anthropic, and others are expected to counter within weeks or months. As one unnamed OpenAI researcher suggested, the frantic development cycle may have only bought "4–6 weeks of breathing room".
For users and developers, the outcome of this high-stakes competition is a clear acceleration in capability. GPT-5.2 represents a tangible leap, particularly for knowledge work. Yet, it also underscores a new reality: in the battle for AI supremacy, no lead is safe, and every release is both an achievement and a preparation for the next inevitable challenge.